Navigation auf uzh.ch
Navigation auf uzh.ch
This is an overview of research projects pursued by Curdin Derungs, leader of the GIS Group from 2014 until mid 2018, and his team colleagues.
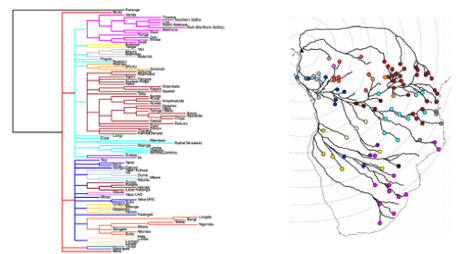
There are contested theories on the expansion of Bantu languages, most centrally involving debate between two paradigms: one positing an early-split and the other a late-split model. We aimed at reconstructing the most probable expansion of Bantu languages, starting in Nigeria and from there, following the paths associated with least travel costs, towards the east and south. We thus conducted a least cost path analysis with the aim of spatially reconstructing the Bantu language tree. Results are published in Christian Wirth's master thesis Modellierung der Ausbreitungspfade der Bantu-Sprachfamilie mithilfe Geographischer Informationssysteme (PDF, 4 MB) (September 2014), supervised by Curdin Derungs, Robert Weibel and Balthasar Bickel.
Dialect data, for instance regarding different syntax practices in Switzerland, often share the same characteristics: they tend to be unevenly distributed in space (in particular if collected through online questionnaires or mobile apps), with varying numbers of answers per location, and each linguistic feature may take on a different number of categorical values. For this reason, we decided to develop a toolbox that would formalize a standard spatial analysis workflow for dialect data. The analysis includes visual as well as statistical output and allows conducting a large series of tests one step at a time.
This project was set up in close cooperation between Elvira Glaser and Philipp Stöckle as part of the SNSF-project "Modelling morphosyntactic area formation in Swiss German (SynMod)" and the GIS Group.
Only recently have large compilations of typological data been homogenized and made freely available to the public. Such information usually comes in the form of a matrix containing some four to six hundred categorical (i.e. multinomial) linguistic features for several hundred global languages (i.e. large-p/small-n, with n actually not being so small). One of the overarching questions that might be answered with such data is: What is the global relatedness of languages and which historic linguistic theory does it support? However, the challenges in using the data for this purpose are, for instance, its categorical character, its large-p, its uneven spatial distribution, and the many NA values, etc. For this reason, we introduced a procedure that reduces dimensionality while still reflecting the impact of individual linguistic features and NA values in particular. Additionally, our approach accounts for the spatial character of the data and thus combines dimension reduction with spatial analysis.
The global distribution of morphological structures of different language families is uneven. This project aims to explain the impact of language contact on morphology through a combination of historical linguistics, phylogeny, and geographic analysis. In the first stage of the project, we gained the necessary background in the relevant linguistic theories. In the second stage, we applied these insights, in combination with new methodological approaches, to regions only associated with sparse historical linguistic information. Collaboration with SNSF sinergia project "Limits of Morphology in Time and Space" (LiMiTS).
The Dogon language family, which consists of some 20 languages, is distributed over an area the size of Switzerland and is located in Mali along the border of Burkina Faso. On the one hand, Dogon languages have not yet been fitted into the puzzle of African languages. On the other hand, they represent a complex spatial pattern of linguistic diversity along a large and often impenetrable natural cliff (the Bandiagara). The goal of this project is to quantify the influence of the Bandiagara and to test if accessibility can account for some of the unexplained linguistic features such as extensive lexical borrowing. Cooperation with Steven Moran and Balthasar Bickel.
The general goal of this project is to explore user-generated descriptions and to develop suitable methods for working with large corpora. In particular, we are interested in examining the way people address their experiences in non-urban natural space through the prism of alpine narratives found in blogs and on alpine clubs’ webpages. The starting point of the research is the non-universal character of space conceptualizations and its dependency on various aspects of context. We aim to study these aspects – those related to the physical world (such as the scale of activity), as well as those related to socially- and individually-dependent constructs (such as the sense of place). By focusing on a specific set of linguistic features – for example, landscape terms – we want to determine how they are used in different ways across different contexts. This project constitutes the PhD thesis of Ekaterina Egorova, supervised by Ross Purves and Thora Tenbrink (Cognitive Linguistics Group, Bangor University). The PhD project is completed (PhD thesis defense April 12, 2018).
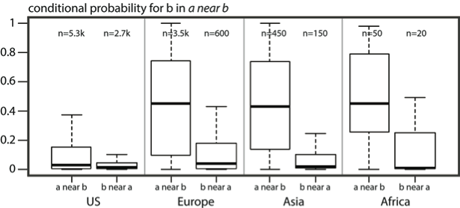
The idea that corpora of written language contain interesting insights on the way people perceive the world, although being established, is not representatively covered in Geography yet! In this project we use Ngrams (n-word combinations in connection with frequencies/probabilities), and associated probabilities, as an entry point to the Internet’s information. In particular, we use Ngrams containing the spatial relation - "near" - in combination with place names. This allows us to georeference a large number of "near relations," distributed over several continents and different geographic settings. Thus, the collection of near instantiations from Ngrams offers the possibility for quantitative interpretations of where and what is near.
Ngrams (n-word combinations in combination with frequencies/probabilities) are used to index large bodies of written text. In recent years, Google as well as Bing allowed access to their Ngram collections representing all one to five word combinations on the Internet (i.e. hundreds of billions of web pages). This information has often been used in different scientific domains (e.g. computer linguistics, artificial intelligence, genetics, etc.). Geography, however, has fallen somewhat short in using Ngrams for spatial analysis or for learning about the use of geographic concepts. One important reason for this gap is that Ngrams are particularly challenging for georeferencing, which is a precondition for follow-up analyses. In this project, our aim is to find means for associating arbitrary words or word combinations with spatial footprints, which in turn opens the door for an in-depth spatial analysis of a broad set of geographic research issues.