Navigation auf uzh.ch
Navigation auf uzh.ch
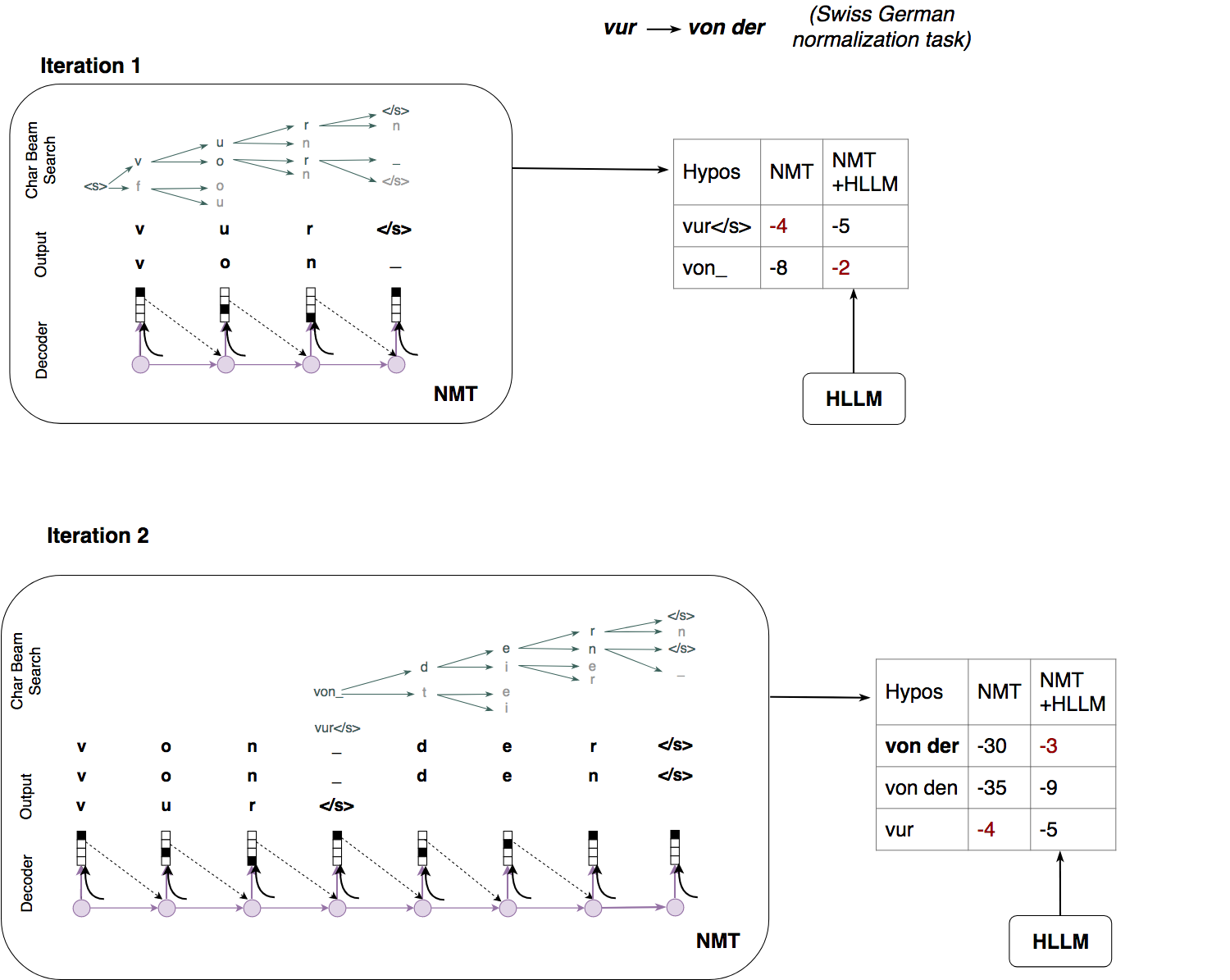
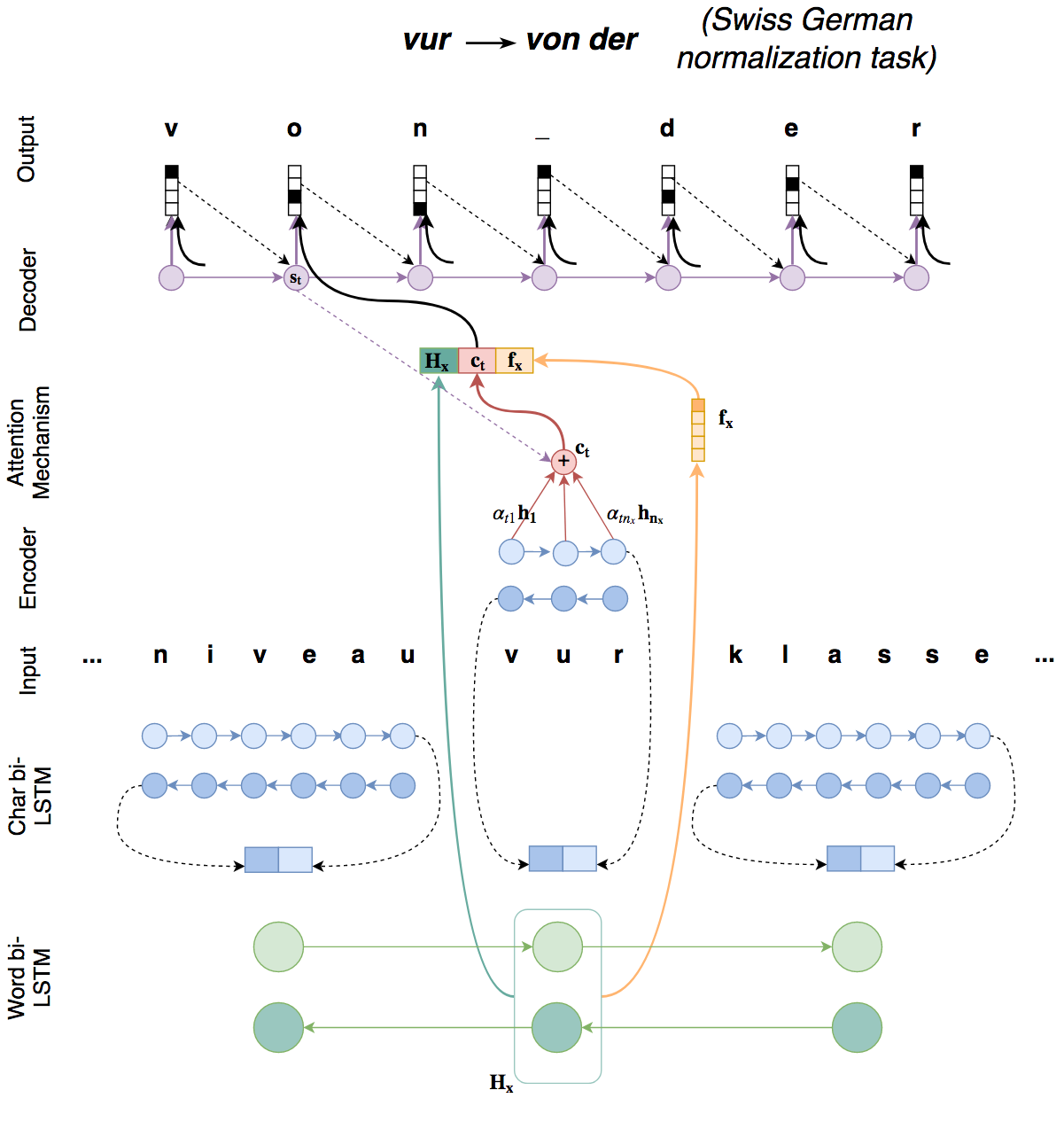
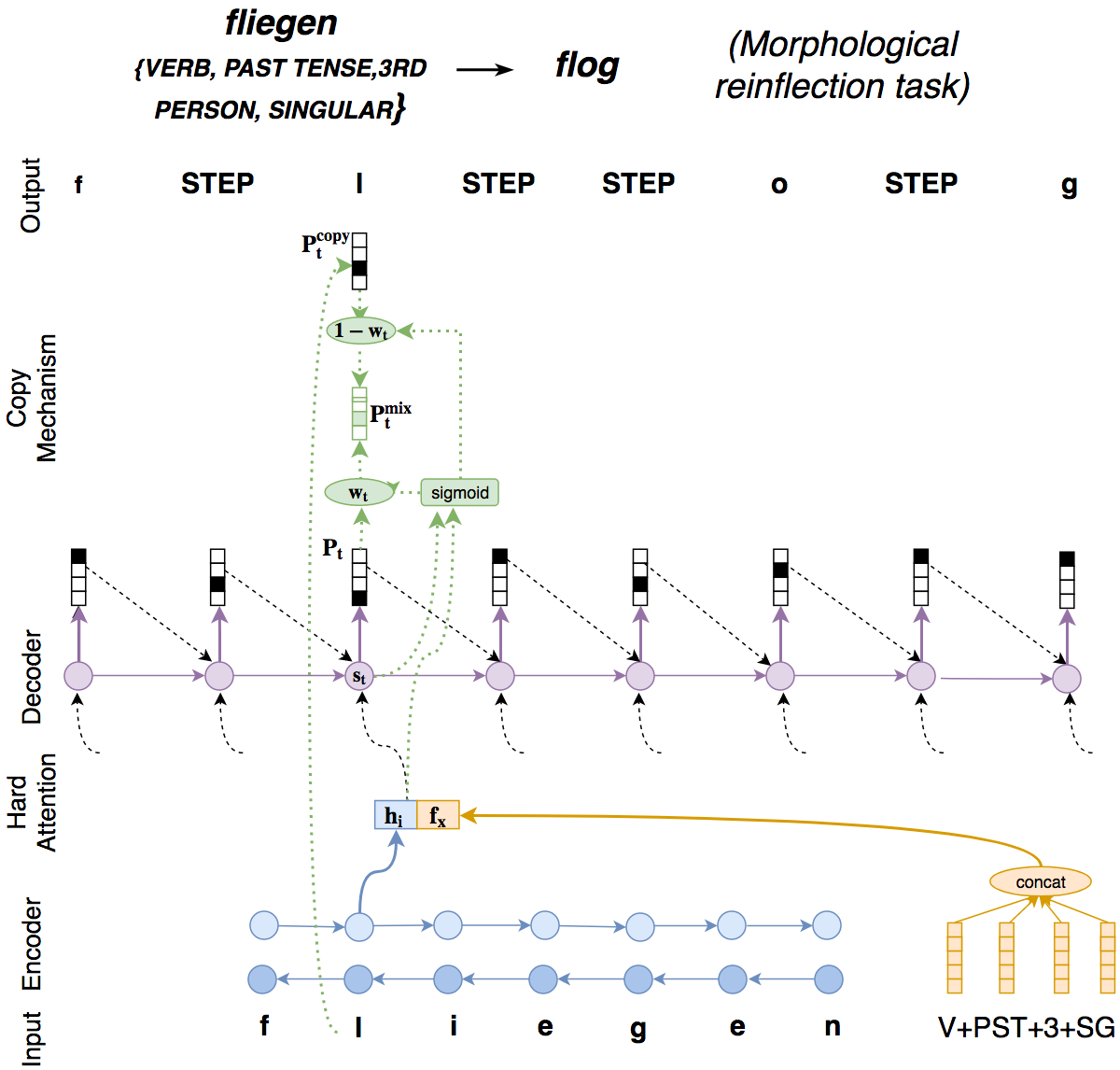
Many practical applications in Natural Language Processing (NLP), such as machine translation and speech recognition, benefit from text preprocessing steps which reduce data sparsity. For example, morphological text processing can help reduce sparsity through segmenting words into morphemes (morphological segmentation) or mapping inflected forms of words to their lemmas (lemmatization). Another example is normalization of writing: mapping surface word forms to their canonical forms through reducing dialectological variation or correcting spelling errors. In many cases, such upstream tasks can be formulated as sequence transformation tasks and solved with the same neural sequence-to-sequence technology that is used in neural machine translation (NMT) and speech processing. In this project, we develop systems for a range of upstream tasks by enriching character-level sequence-to-sequence models with structural signal derived from multiple text organization layers: characters, morphemes, words and sentences.
Project members: Tatiana Ruzsics (PhD student) and Tanja Samardžić (PI).
Funding: URPP "Language and Space" (UZH internal)
Ruzsics, T. and T. Samardžić (2017). "Neural Sequence-to-sequence Learning of Internal Word Structure"
Ruzsics, T. and T. Samardžić (Draft). "Multilevel text normalization with sequence-to-sequence networks and multisource learning" . ArXiv
Makarov P., T. Ruzsics, and S. Clematide (2017). "Align and copy: UZH at SIGMORPHON 2017 shared task for morphological reinflection"