Navigation auf uzh.ch
Navigation auf uzh.ch
The project applies information theory, statistical modelling and machine learning to the study of language adaptation using linguistic data extracted from multilingual corpora. In addition to the theoretical findings, the project will provide a data set consisting of text samples of 100 languages facilitating future use of corpus-based computational methods in scientific approaches to linguistic diversity and change.
Project members: Olga Sozinova (PhD student), Ximena Gutierrez-Vasques (PostDoc), Christian Bentz (PostDoc, external collaborator), Steven Moran (PostDoc, external collaborator) and Tanja Samardžić (PI).
Funding: SNF grant #176305 2018—2022.
Steven Moran, Christian Bentz, Ximena Gutierrez-Vasques, Olga Sozinova and Tanja Samardzic. 2022. "TeDDi Sample: Text Data Diversity Sample for Language Comparison and Multilingual NLP”. In Proceedings of The International Conference on Language Resources and Evaluation (LREC), Marseille, France. 20—25 June 2022.
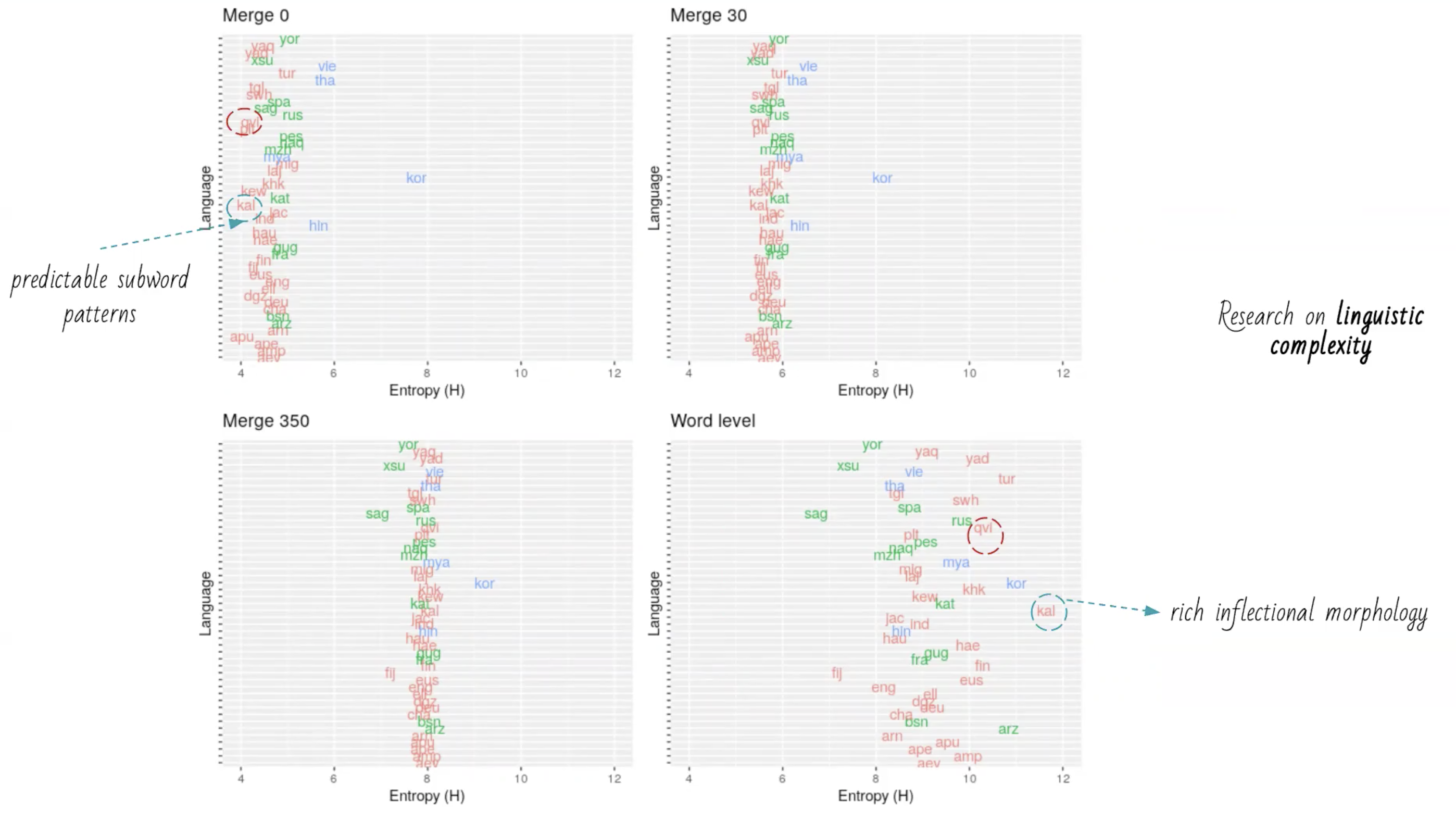
Ximena Gutierrez-Vasques, Christian Bentz, Olga Sozinova and Tanja Samardzic. 2021. "From characters to words: the turning point of BPE merges”. European Chapter of the Association for Computational Linguistics, Long Papers.
Paper GitHub repository Twitter thread Video

Tatyana Ruzsics, Olga Sozinova, Ximena Gutierrez-Vasques and Tanja Samardzic. 2021. "Interpretability for morphological inflection: from character-level predictions to subword-level rules”. European Chapter of the Association for Computational Linguistics, Long Papers.